메타데이터 매핑을 이용하면 데이터베이스 매핑 작업 을 크게 간소화할 수 있다.
대신 메타데이터 매핑을 프레임워크를 준비하는 작업이 필요하다.
MyBatis의 ResultMap 그것과 비슷하다.
쿼리 객체
데이터베이스 쿼리를 나타내는 객체
인터프리터[GoF] 역할을 한다. 객체의 구조를 바탕으로 SQL 쿼리를 구성할 수 있게 해준다.
SQL
Composite pattern
DSL
구현
쿼리 객체의 기본은 데이터베이스의 스키마가 아니라 인메모리 객체를 기준으로 쿼리를 표현하는 것이다.
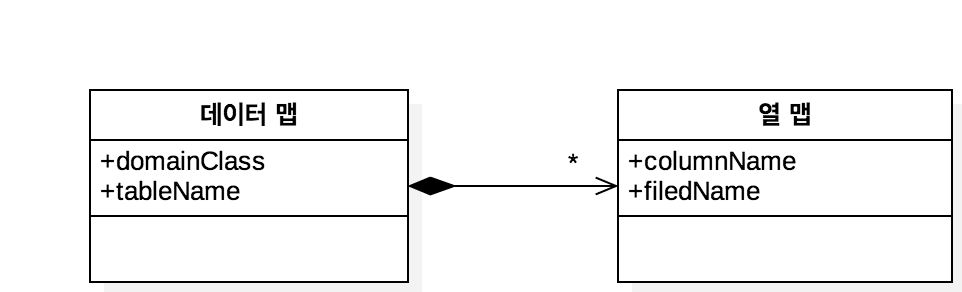
고로 메타데이터 매핑(325) 가 필요하다.
장점
데이터베이스 스키마 캡슐화
다중 데이터베이스 지원
다중 스키마 지원
중복 쿼리 방지
대부분의 프로젝트는 모든 쿼리 기능을 필요하지 않으므로 제한된 쿼리 객체 만으로 충족할 수 있다.
추가 스팩이 생기면 그 때 반영해도 늦지 않다.
리포지토리
도메인 객체에 접근하는 컬렉션과 비슷한 인터페이스를 사용해 도메인과 데이터 매핑 계층 사이를 중재한다.
Persistence 계층에 대한 좀 더 객체지향적 관점을 제공한다. 또한 도메인과 데이터 매핑 계층 간의 깔끔한
분리와 단방향 의존성의 목표를 달성하도록 지원한다. (데이터 매핑 캡슐화)
리포지토리는 순수한 객체지향 방식으로 수행할 수 있게 캡슐화 하는 사양패턴(Specification pattern)을
촉진힌다. 그래서 특정한 사례에 맞게 쿼리 객체를 설정하는 코드를 모두 제거할 수 있다. 또한 클라이언트는
SQL을 직접 다루지 않고 순수한 객체의 관점에서 코드를 작성할 수 있다.
분기문이 객체지향적 사고를 방해한다고 하였지만, 역으로 프로그래밍에서 논리 처리를 위해서 분기문은 필수로 필요합니다.
하지만 분기문을 적절하게 사용하지 못하면 가독성을 방해하고 유지보수 하기 힘든 코드로 만듭니다. 이와 관련해서
특히 분기문을 통해서 유효성 처리를 하는 경우 적절한 분기처리 숙어(idiom)를 알려드리겠습니다.
보호절 숙어
기존
voidinitialize(){if(!isInitialized()){// 적절한 초기화 로직}}
개선
voidinitialize(){if(isInitialized()){return;}// 적절한 초기화 로직}
기존과 개선을 비교하면 도찐개찐 인 거 같습니다. 하지만 두번째 예제를 보면 생각이 달라질 겁니다.
기존 - 중첩 if
voidcompute(){Serverserver=getServer();if(server!=null){Clientclient=server.getClient();if(client!=null){Requestcurrent=client.getRequest();if(current!=null){// 실제 처리할 로직processRequest(current);}}}}
개선 - 중첩 if
voidcompute(){Serverserver=getServer();if(server==null)return;Clientclient=server.getClient();if(client==null)return;Requestcurrent=client.getRequest();if(current==null)return;// 실제 처리할 로직 processRequest(current);}
기존과 개선의 차이가 느껴지십니까?
일반적으로 개발할 시 긍정적(유효한) 상황을 염두하고 개발을 진행하게 됩니다.
그래서 계속 적으로 유효성 체크 로직이 포함할 시에는 마치 계층(hierarchy) 구조를 보는 것 같습니다. - 기존
하지만 이를 역으로 부정적(유효하지 않는 상황) 상황을 염두하고 분기처리하면 선형(linear) 구조를 취합니다. - 개선
고로 더 나은 가독성과 구조를 제공하는 것입니다.
이를 보호절 숙어라고 부르는데 실제 처리할 로직이 처리되기 전에 유효하지 않는 상황으로 분기되면
해당 지역(메서드, 루프 블록 등)을 벗어나게 하는 것입니다. 보통 return을 하거나 예외(Exception)를 발생시킵니다.
그럼 loop 구문 내 분기는 어떻게 처리하면 될까요?
while(line=reader.readline()){if(line.startsWith('#')||line.isEmpty())continue;// 실제 처리할 로직}
continue를 이용하면 유사하게 처리할 수 있습니다.
가독성을 위한 if
조건문에서 인수의 순서
if(10<=length)// 아래가 더 낫다.if(length>=10)
좌변에 유동적인 값이나 표현을 넣고, 우변에 상수와 같은 고정값 표현을 넣어야지 가독성이 좋음
if/else 블록의 순서
가능한 if에는 긍정의 조건을 넣어야지 가독성이 좋음.
두 블록 중 간단한 블록을 먼저 if에 둠
더 흥미롭고, 확실한 것을 if절에 먼저 보이게 한다.
// 가능하면 긍정적인 조건 ex:hasAccountif(...){// 간단하고 긍정적인 내용}else{/*
* 상대적으로 복잡함
* ...
* ...
*/}
단 보호절 숙어가 우선순위가 높음 if가 계층구조로 중첩될 거 같은데 부정의 조건을 넣어서 계층구조가 사라지면 이것이 더 낫다는 말임
삼항연산자
간단한 구문일 경우 : 삼항연산자
복잡한 구문일 경우 : if/else
삼항연산자는 코드 한 라인으로 적절한 가독성을 확보할 수 있을 때 사용하며,
만약 한 라인으로 처리하기 복잡할 경우에는 if/else를 쓰는 것이 훨씬 유리하다.
if(request.user.id==document.owner_id){//사용자가 이 문서를 수정할 수 있다.}...if(request.user.id!=document.owner_id){//문서는 읽기 전용이다.}
개선
finalbooleanisOwner=this.isOwner(request,document);if(isOwner){//사용자가 이 문서를 수정할 수 있다.}...if(!isOwner){//문서는 읽기 전용이다.}...privatebooleanisOwner(Requestrequest,Documentdocument){returnrequest.user.id==document.owner_id;}
재사용 되거나, 혹여 재사용되지 않더라도 분기절내의 복잡한 내용을 메소드로 표현하게 되면 더 나은 가독성을 얻을 수 있다.
...// begin이나 end가 other에 속하는지 확인privatevoidoverlapsWith(Rangeother){// 우리가 시작하기 전에 끝난다.if(other.end<=begin)returnfalse;// 우리가 끝난 후에 시작한다.if(other.begin>=end)returnfalse;// 겹친다.returntrue;}...
무리하게 한 라인으로 논리를 표현하지 않고 가독성 확보를 위해 적절하게 여러 라인으로 분리한다. - 보호절의 그것과 유사하다 -
실제 개발을 진행하다보면 if-else 구문이나 switch-case 구문을 정말 많이 사용하게 됩니다.
논리적 사고 방식을 기반으로 할 시 분기 처리는 필수적인 영역인데 이 때 유용하게 사용할 수 있습니다.
하지만 절차적 프로그래밍에서 객체지향적 프로그래밍으로 패러다임 전환 이 일어나면서 로직 분기문은
과거 절차적 프로그래밍의 유산으로 객체지향적 사고방식을 방해하는 요소 중 하나가 되었습니다.
제가 현업에서 업무를 진행할 시 팀원들에게 가장 많이 하는 말 중에 하나가 가능한 분기문을 없애야 한다.
입니다. 그런데 해당 내용에 대해서 말로써 표현을 할려고하니 이해가 힘든부분이 있어서 이렇게 포스팅을 하게
되었습니다.
단순 반복적인 분기문을 최소화하려는 노력을 기울이면 그 댓가로 객체지향적 사고와 코드 를 얻을 수 있습니다.
좀 더 일반화 하면 DRY(중복배제) 를 지킬려고 하는-boiler plate한 코드를 줄일려는- 노력을 하다 보면
그 해답 중 하나인 객체지향적 사고방식 을 얻을 수 있습니다.
아래 예제를 통해서 알아보겠습니다.
쇼핑몰 할인정책
많은 분들이 이해하기 쉬운 쇼핑몰 도메인으로 예제를 꾸며 보았습니다.
같은 종류의 분기처리가 코드 곳곳에서 중복해서 발생하는데 처리하는 도메인 로직은 미묘하게 다른 경우가 많죠.
실제 아래와 같은 코드를 현업에서 정말 많이 볼 수 있습니다.
위와 같이 getDiscountAmt 메소드 추출만 하는 것만으로 코드의 중복이 제거되고 깔끔해졌습니다.
하지만 우리의 목표는 여기가 아닙니다. 위와 같은 메소드 추출은 기존 절차적 프로그래밍에서 가능한 리팩터링
기법입니다. 여기에서 중요한 것은 getDiscountAmt 즉 할인에 관한 정책 분기를 결제 서비스
객체의 책임으로 두는게 맞느냐 입니다. 할인과 결제는 분리되는 것이 나은 것 같습니다.
두 관계를 더 구제척으로 톺아보면 쇼핑몰 도메인 상 할인과 결제가 연관관계(Association)를 가지고는
있으며, 강결합이 아닌 유연성을 가져야합니다.
또한 이 객체 뿐만 아니라 다른 객체에서 할인 로직을 사용할 시에는 getDiscountAmt 메소드가 또 중복으로
발생하게 됩니다. if-else도 같이 중복되겠죠.
여기에서부터 추상화 시각 이 필요합니다. 추상화 시각을 바탕으로 추상화할 영역을 추출해야합니다.
추상화를 시도할 시 책임(역할)을 기반으로 분리할 도메인 로직의 핵심을 집어내야합니다. 현재 예제에서 분리할
도메인 로직은 바로 할인 입니다. 할인 로직의 핵심은 바로 할인금액을 구하는 것이라고 할 수 있죠.
즉 getDiscountAmt 가 분리할 핵심적인 행위(메소드)가 되며, 추상화 시키면(interface) 되는 것입니다.
추후에 설명 드리겠지만 여기에서 행하는 추상화는 바로 일반화 가 되겠습니다.
이제 할인할 수 있는(할인 금액을 구하는 것) 추상화를 기반으로 해당 인터페이스를 추출하겠습니다.
구현을 간단히 설명하면 각 할인정책이 하나의 클래스로 분리된다고 보시면 됩니다. 이러한 리팩터링 기법을
인터페이스 추출 이라고 부릅니다.
기본적으로 클래스 추출 후 다형성이 요구될 경우 인터페이스 추출을 하지만 클래스 추출 과정은 생략 하였습니다.
클래스 추출 자체가 강결합이고 `SRP`(책임분리)만 충족할 뿐 더 중요한 유연성는 만족하지 못하기 때문입니다.
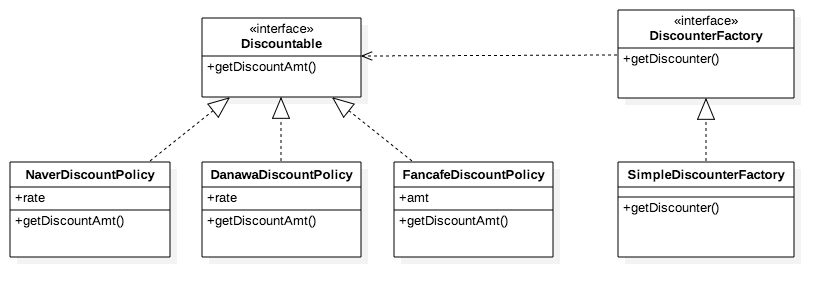
인터페이스를 적절하게 추출하였으나, 팩토리 메소드가 해당 객체 내에 있기 때문에 아직 완벽하게 클라이언트
(PaymentService) 객체와 할인 구상클래스가 강결합 상태입니다. 현재 상태로 봐서는 메소드 추출 시점과
별로 나아진 점이 없네요. 아직 리팩터링이 부족합니다.
getDiscounter(String) 팩토리 메서드. 즉 할인정책을 생성하는 메소드도 분리해야 할 것 같습니다.
이번에도 이전과 마찬가지로 인터페이스 추출을 시도할 건데 여기에서 분리할 것은 바로 할인 정책 생성
입니다.
discounterFactory=newSimpleDiscounterFactory();// 실시간 할인내역 확인publicDiscountgetDiscount(...){...}// 결제처리publicvoidpayment(...){...}privateDiscountablegetDiscounter(StringdiscountCode){returndiscounterFactory.getDiscounter(discountCode);}
이제야 깔끔하게 역할이 분리되었으며, 추상화를 바탕으로 유연함의 기틀이 마련되었습니다.
리팩토링 후 정리
역할(책임)
결제 : PaymentService
할인 : Discountable
할인생성 : DiscounterFactory
유연성확보(기존과 동일)
DIP를 통해서 강결합의 구상클래스가 아니라 유연한 인터페이스를 바탕으로 객체 의존성 확보
클래스 다이어그램
위 패턴을 사용하면 코드 중복을 없애기 위해 90% 이상 템플릿 메소드 패턴 을 병행해서 사용하게 됩니다.
위 예제는 템플릿 메소드 패턴을 적용할 필요가 없어서 사용하지 않았습니다.
참고로 템플릿 메소드 패턴은 자바에서 귀중한 상속(extends)을 사용하기 때문에 주의를 요합니다.
주류적인 행위에 대한 것이 아니면 해당 패턴을 사용하는 것보다는 헬퍼클래스 구성을 통한 위임 을 이용하는 것을 추천
합니다.
이 정도 리팩터링 해도 객체지향적이다 라고 말할 수 있습니다. 만약 새로운 할인 정책이 추가되면 PaymentService와
같은 클라이언트들은 변경할 필요 없이 Discountable를 확장하여 새로운 할인정책 구상클래스를 추가하고,
SimpleDiscounterFactory에 else if 하나만 추가하면 기능 확장이 가능한 것입니다.
하지만 OCP를 만족하지는 못했습니다. 비록 PaymentService에 대해서 변경은 없지만
이미 구현된 SimpleDiscounterFactory 에서 변경이 발생하기 때문입니다. (else-if 추가해야함)
또다른 시선
잠깐 다른 방향으로 리팩터링을 해보는 것도 알아보겠습니다.
만약 다루는 속성(데이타)이 정적이라면 Simple Factory 대신 enum을 사용하는 것을 고려해봐도 좋습니다.
@Slf4jpublicclassPaymentService{// 실시간 할인내역 확인publicDiscountgetDiscount(...){...}// 결제처리publicvoidpayment(...){...}privateDiscountablegetDiscounter(StringdiscountCode){if(discountCode==null)returnDiscountable.NONE;try{returnDiscountPolicy.valueOf(discountCode);}catch(IllegalArgumentExceptioniae){log.warn("Not found discountCode : {}",discountCode);returnDiscountable.NONE;}}...
위와 같이 enum 별로 할인 인터페이스를 구현하게 만들어서 깔끔한 코드를 만들 수 있습니다.
이전의 Simple Factory과는 달리 분기문 자체가 아예 필요없고, 확장도 enum 상수를 하나 구현하면 되므로,
더 나아보입니다.
거기에다가 enum 상수 추가 만으로도 그 외에 코드 변경 없이 확장(신규 할인정책 추가)이 가능합니다.
하지만 위에서도 언급했다시피 데이타가 정적 즉 변화할 가능성이 없는 객체를 다룰 경우에만 사용하는 것이 좋습니다.
단점을 살펴보면
enum 사용 시 단점
enum이기 때문에 상태가 변화할 수 없다.
상속이나 확장이 일부 제한되기 때문에 유연성이 조금 떨어진다.
만약 예를 들어서 네이버의 할인율이 10%인데 갑자기 15%로 변경될 경우 어플리케이션을 다시 배포해야 합니다.
물론 위 Simple Factory 패턴을 이용할 경우에도 마찬가지 입니다만, 조금 더 개선하면 유연하게 대응할 수 있습니다.
예제 흐름 상 Factory를 남겨두었으나 PaymentService에서 바로 DiscounterRepository를 주입받아서 쓰는 것이 의미 상 더 명확합니다.
@ServicepublicclassPaymentService{@AutowiredDiscounterFactorydiscounterFactory;// 실시간 할인내역 확인publicDiscountgetDiscount(...){...}// 결제처리publicvoidpayment(...){...}privateDiscountablegetDiscounter(StringdiscountCode){returndiscounterFactory.getDiscounter(discountCode);}...
Java8, 스프링 프레임워크와 JPA를 사용한다는 가정으로 예제코드를 표현했습니다.
with JPA
변경하는 값을 조회하기 위해서 Repository를 사용하였습니다.
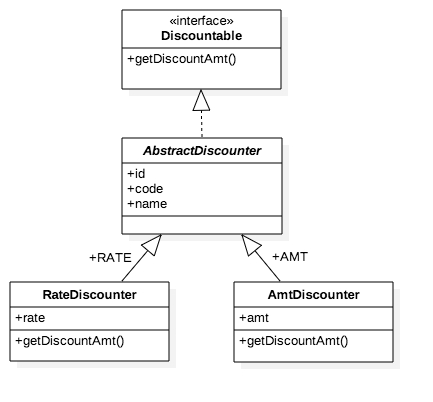
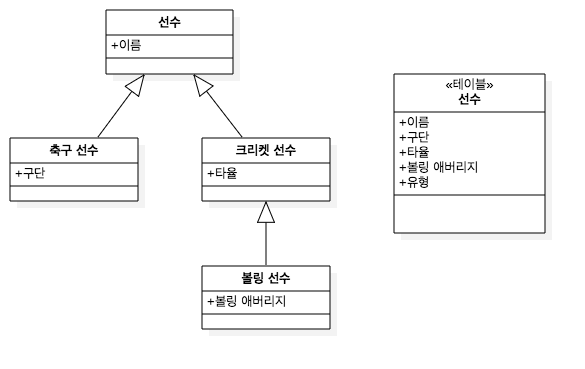
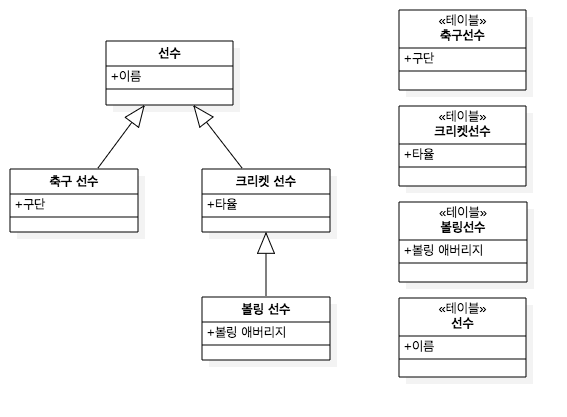
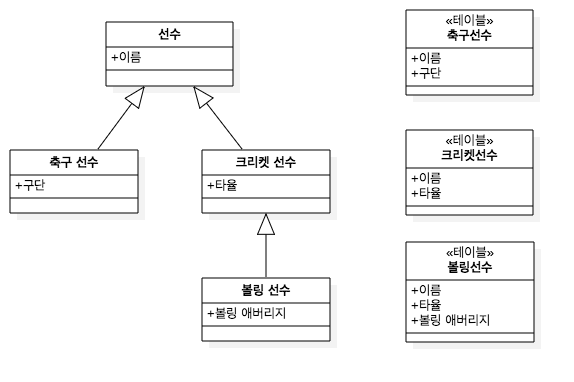
다형성을 위해서 상속 관계 매핑 을 이용하였습니다.
상속 관계 매핑 다이어그램
현업에서는 복잡한 도메인 로직이 많습니다. 위 예와 같이 만약 네이버 할인이 15%로 변경할 경우
이전과 같은 방식으로 구현할 시에는 어플리케이션을 재배포 해야 대응이 가능합니다. 근본적인 원인은
엔터프라이즈 어플리케이션에서 대부분의 객체는 상태가 언제나 쉽게 변하는(mutable) 객체(Entity-도메인 객체) 이기 때문입니다.
도메인 로직을 품은 객체의 상태가 정적인 경우는 거의 없습니다.
변하지 않는 것은 모든 것은 변한다는 사실뿐이다. -톰피터스
이렇게 구성하면 분기문으로 처리할 내용을 각각의 Entity 객체로 분리해서 처리하면 되어서 분기문을 최소화
(또는 제거)할 수 있으며, 자주 변하는 요구사항과 객체 상태의 변화(할인정책 변화)에 대해서도 유연하게
대응할 수 있게 됩니다.
숨겨진 리팩터링
코드를 잘 보시면 RateDiscounter(할인율), AmtDiscounter(금액할인) 두개의 구상 클래스가 있는 것이 확인됩니다.
기존에 NaverDiscountPolicy, DanawaDiscountPolicy를 보면 할인율을 통한 할인이라는 같은 로직을 같는 클래스 였는데,
각각 구현되는 것을 분류를 통해서 RateDiscounter로 추상화 시킨 것입니다.
만약 구글 20% 할인 같은 정책이 추가되면 Discounter 테이블에 해당 정책을 하나 추가하면 됩니다.
전혀 코드 변경 없이 정책 확장이 가능하게 되는 것입니다. 그리고 해당 할인금액을 조회하는 행위(메소드)도
Entity 안에 있기 때문에 객체지향의 근본인 연관된 상태와 행위가 가지는 객체가 되어서 더욱 응집력이 높아집니다.
Bonus Step 3-2. With Mybatis
현재 현업에서는 아직도 Mybatis 같은 SQL매퍼를 이용하거나,jdbc기반으로 사용하는 곳이 많습니다.
반환타입으로 Map가 아닌 DTO를 사용하신다면 이용할 수 있는 예제도 보너스로 준비해 보았습니다.
불행하게도 Mybatis를 사용할 경우 상속관계를 표현할려면 상당한 추가 작업이 요구되는데, 대부분의 경우 그런 과정을
사용하지 않고 Data 기반으로 구현하기 때문에 Step 3 예제와는 다른 방식으로 분기처리를 풀어보겠습니다.
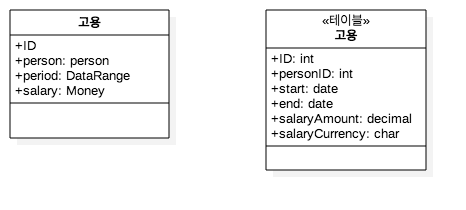
기본적으로 테이블 구조는 동일하게 가겠습니다. 어짜피 상속을 표현하기 힘들기 때문에 대부분 단일 테이블 형태를 사용합니다.
Discounter 테이블
*id
dtype
*code
name
rate
amt
1
RATE
NAVER
네이버
10
0
2
RATE
DANAWA
다나와
15
0
3
AMT
FANCAFE
팬카페
0
1000
테이블과 연관된 DTO를 하나 생성하고 Discounter 인터페이스를 구현하게 합니다.
Mybatis Dao 구현 코드는 생략하겠습니다.
Mybatis를 사용할 경우 대부분 객체의 상태(속성)만 관리를 하고 연관되는 행위는 다른 컴포넌트나 Service 계층에서
직접 핸들링하는 경우가 많습니다. 하지만 생각을 전환해서 이렇게 DTO(하지만 실질적으로는 Entity 성격이 강함) 내에 두는 것이 좋다고 봅니다.
하지만 if절이 또 여기에서 생기네요.
@DatapublicclassDiscounterDtoimplementsDiscountable{publicLongid;// myabtis도 커스텀컨버터를 이용해서 String - enum 간 변환이 가능하다.publicDiscountTypedtype;publicStringcode;publicStringname;publicintrate;publiclongamt;@OverridepubliclonggetDiscountAmt(longoriginAmt){returndtype.getDiscountAmt(this,originAmt);}}
다시 강조하지만 객체의 상태는 동적이지만 객체의 행위는 정적입니다. 행위에 인자가 동적이어서 행위를 통해서
객체의 상태가 행위의 반환이 변경될 뿐이지 행위 자체는 정적이라고 보시면 됩니다.
간단하게 예를 들어서 A + B = C 일 때 A, B, C와 같은 값은 변하지만 + 즉, 더하기 연산은 변하지 않습니다.
이러한 정적인 영역인 할인계산 부분을 enum 정책으로 관리하고 계산하는 로직에 DTO에서 위임하면 됩니다.
중요한 것은 비록 ORM을 사용하지 않더라도 도메인 로직을 객체 내에 담자 라는 것입니다.
이렇게 구성하면 추후 새로운 정책 추가/변경, 모델(테이블스키마)이 변경되더라도 어느정도의 유연성은 확보할 수 있습니다.
결론
궁긍적으로 분기문을 없앨 수는 없습니다. 특히 유효성 체크와 같은 분기문은 계속 유지되어야 합니다.
제가 위에서 말하는 것은 도메인 로직을 분기하는 분기문을 복수 번 반복하게 하는 것이 아니라 최소 1번 또는
하나의 구상 클래스 내에서 복수 번 관리하게 되어서 같은 종류의 로직 분기문이 코드 곳곳에서 발생하는 것을
방지하기 위해 노력하자 이며, 과정을 보여주고 싶었습니다.
또한 이러한 속성과 깊은 관계가 생기는 로직이 있을 시 디자인패턴을 이용하는 것 보단 도메인 모델 안에서 처리하는 것이 가장 좋고 간단한 방안이 될 수 있는 것을 보여주고 싶었습니다.
Domain model with JPA 짱짱맨????
객체지향적 프로그래밍을 통해서 로직분기문을 최소화하는 노력을 기울이면 유연하고 응집력 있는 코드를 생성하자
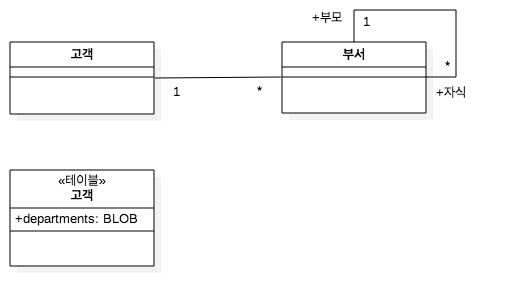
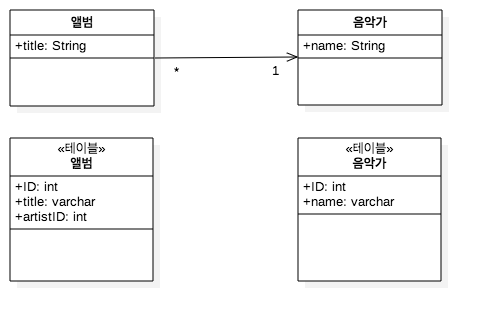
인메모리 객체와 데이터베이스 행 간의 식별자를 유지 관리하기 위해 데이터베이스 ID 필드를 저장하는 객체
고려사항
DB 키 선택
자연키 or 대리키
단일키 or 복합키
키의 형식 : 정수 or 문자열
객체 식별자 필드
형식 일치 필드(정수키 = 정수필드)
키클래스(복합키)
새로운 키 생성
DB 자동 생성
GUID(Globally Unique IDentifier) : 해시코드
직접 키 생성
SELECT MAX(IS_NULL(seq, 0)) + 1 FROM TABLE
키 테이블
외래 키 매핑
객체 간 연결과 테이블 간 외래 키 참조의 매핑
고려사항
삭제 및 삽입
데이터 변경 일관성 유지
all delete and insert
diff : 변경 부분만 반영
역참조 추가
양방향 객체 관계 설정
컬렉션 차이
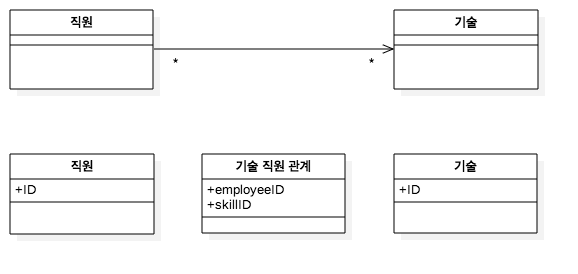
1:N or N:1 or N:M
연관 테이블 매핑
N:M
의존 매핑
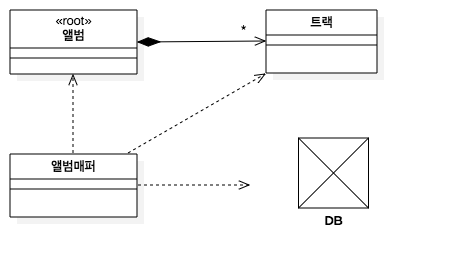
한 클래스가 자식 클래스의 데이터베이스 매핑을 수행하게 한다.
예를들어
앨범의 트랙은 해당 트랙이 속한 앨법이 로드되거나 저장될 때마다 함께 로드되거나 저장될 수 있다.
데이터베이스의 다른 테이블에서 참조되지 않는 경우. 앨범 매퍼가 트랙에 대한 매핑까지 처리하게 되면
매핑 절차를 간소화 할 수 있다. 이 매핑을 의존 매핑(Dependent Mapping) 이라고 한다.
DB기준으로 의존자는 복합키(소유자 키 일부포함)이면 더 구현에 유리하다.
UML에서 소유자(앨범)와 해당 의존자(트랙) 간의 관계는 합성(Composition)으로 표시하는 것이 적합하다.