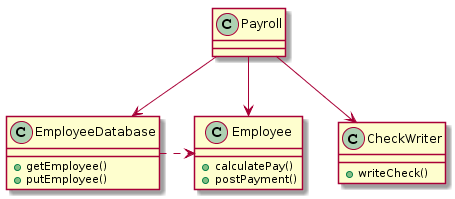
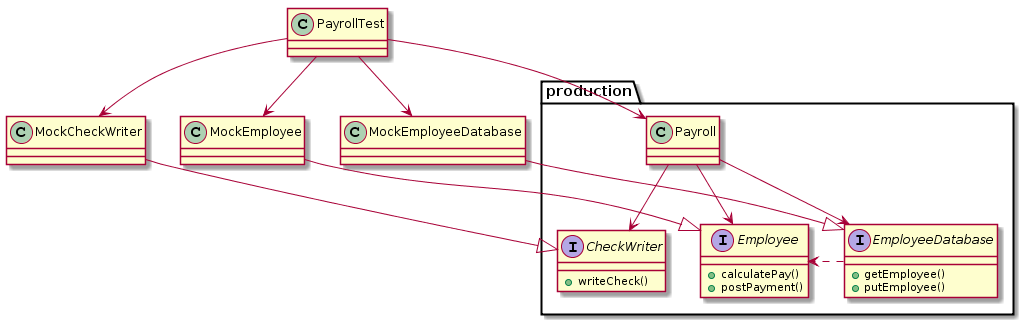
리스코프 치환 원칙(LSP)
리스코프 치환 원칙(LSP)
서브타입(subtype)은 그것의 기반 타입(base type)으로 치환 가능해야 한다.
일반적인 상속 (의 행위) 관한 원칙
LSP 위반은 잠재적은 OCP 위반이다.
IS-A
- 고양이는 동물이다.
- Cat is an Animal
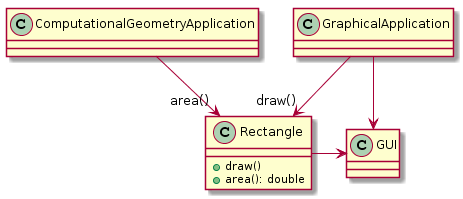
문제
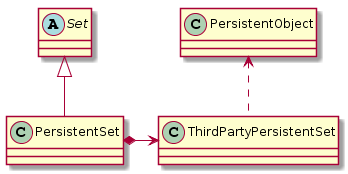
영속 집합 계층구조
하지만 여기에서 Add 메서드가 특정 타입인 경우 PersistentObject에서 파생된 것이 아닌 경우에는 LSP를 위배하게 된다.
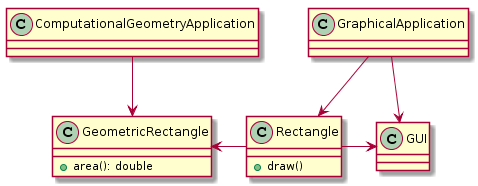
LSP를 따르는 해결책
LSP가 깨지는 메서드는 서브 클래스로 분리하고 문제 없는 메서드는 기반 클래스로 분리한다.
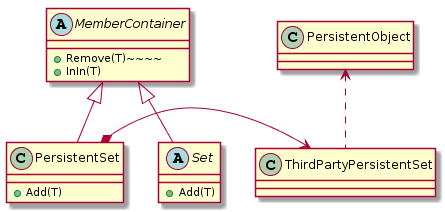
LSP를 따르는 해결책
파생(상속) 대신 공통 인자 추출(인터페이스 분리) 하기
- 최상위에 인터페이스를 하나 선언 (Shape)
- 클라이언트는 해당 인터페이스에 의존하면 됨
- 인터페이스를 구현하는 추상클래스나 클래스를 생성 (Rectangle)
- 그리고 해당 클래스를 구성 해서 인터페이스를 구현하면 됨 (Square)
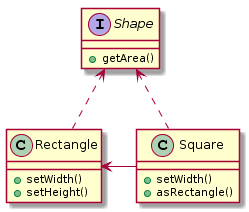
상속(LSP)이 제대로 가능한 경우는 템플릿 메소드 패턴을 이용한 경우인 것 같다. 그 외의 경우라면 그냥 구성하는 편이 나은 것 같다 - 필자생각
휴리스틱과 규정
LSP 위반의 단서를 보여주는 휴리스틱
- 기반 클래스에서 어떻게든 기능성을 제거한 파생 클래스에 대해 적용해야 한다.
- 기반 클래스보다 덜한 동작을 하는 파생 클래스는 보통 그 기반 클래스와 치환이 불가능하므로 LSP 위반
파생 클래스에서의 퇴화 함수
class Base {
public void f() {
// 구현 코드
...
}
class Derived extends Base {
@Override
public void f() {
// 퇴화 시킴
}
}
}파생 클래스에서의 예외 발생
기대하지 않은 예외가 발생하면 위반 가능성이 크다
결론
기반 타입으로 표현된 모듈을 수정 없이도 확장 가능하게 만드는, 서브 타입의 (특히 행위) 치환 가능성을 말한다.
의존 관계 역전 원칙(DIP)
의존 관계 역전 원칙
- 상위 수준 모듈은 하위 수준의 모듈에 의존해서는 안 된다. 둘 다 모두 추상화에 의존해야 한다.
- 추상화는 구체적인 사항에 의존해서는 안 된다. 구체적인 사항은 추상화에 의존해야 한다.
기존의 병폐
- 상위 수준의 모듈이 하위 수준의 모듈에 의존
- 상위 수준의 모듈은 어플리케이션의 본질을 담고 있다.
- 그러나 상위 모듈이 하위 모듈에 의존할 때, 하위 모듈 변경은 상위 모듈에 직접적인 영향을 미칠 수 있고, 나아가서 상위 수준 모듈이 변경되게 할 수도 있다.
- 이런 상황은 말도 안 된다! : 상위 모듈은 어떤 식으로든 하위 모듈에 의존해서는 안 된다.
- 정책이 구체적인 것에 의존
- 정책을 결정하는 것은 상위 수준의 모듈이다.
- 우리가 재사용하기 원하는 것은 정책을 결정하는 상위 수준의 모듈이다.
- 상위 수준의 모듈이 하위 수준의 모듈에 독립적이면, 재사용하기 쉽다.
역전
- 잘 설계된 객체된 객체 지향 프로그램의 의존성 구조는 전통적인 절차적 방법에 의해 일반적으로 만들어진 의존성 구조가 ‘역전’된 것이다.
레이어 나누기
잘 구조화된 모든 객체 지향 아키텍처는 레이어를 분명하게 정의했다. 여기서 각 레이어는 잘 정의되고 제어되는 인터페이스를 통해 일관된 서비스의 집합을 제공한다. - 부치(Booch)
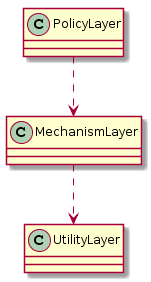
미숙한 레이어
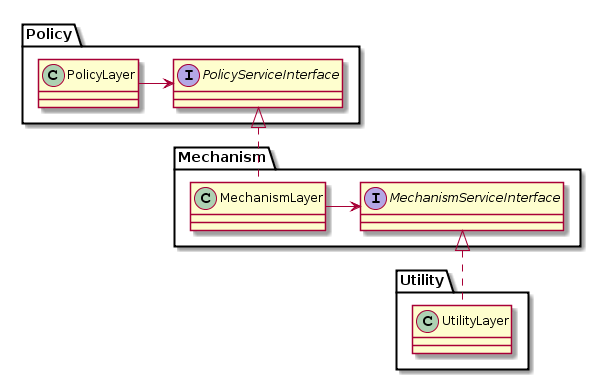
역전된 레이어
그래서 역전은?
- 의존성의 방향을 역전시키고 하위 수준 모듈이 의존 당하는 대신 (인터페이스에) 의존하게 만드는 것
소유권 역전
- 여기서 역전은 의존성 뿐만 아니라, 인터페이스 소유권에 대한 것도 의미한다.
잠깐! 헐리우드 원칙이란?
- 하위 수준 모듈에서 시스템에 접속을 할 수는 있지만, 언에 어떤 식으로 그 모듈을 사용할지는 상위 수준 모듈에서 결정하게 된다.
- 즉, 상위 수준 모듈에서 하위 수준 모듈에
먼저 연락하지 마세요. 저희(상위 수준 모듈)가 먼저 연락 드리겠습니다.라고 말하는 원칙 - DIP와 관계가 깊음
- ex) 전략 패턴, 템플릿 메소드 패턴, 팩토리 메소드 패턴
이렇게 의존성을 역전시킴으로써, 우리는 좀 더 유연하고, 튼튼하고, 이동이 쉬운 구조를 만들 수 있다.
추상화에 의존하자
프로그램의 모든 관계는 어떤 추상 클래스나 인터페이스에 맺어져야 한다고 충고 하는 것
고지식한 원칙
- 어떤 변수도 구체 클래스에 대한 포인터나 참조값을 가져서 안 된다.
- 어떤 클래스도 구체 클래스에서 파생(상속)되어서는 안 된다.
- 어떤 메소드도 그 기반 클래스에서 구현된 메소드를 오버라이드해서는 안 된다. : LSP포함
너무 고지식할 필요까진 없다.
- 상황에 따라서 고지식할 때도 있고, 유연하게 넘겨야할 때도 있다.
결론
- 프로그램의 의존성이 역전되어 있다면 이것은 객체 지향 설계이며, 의존성이 역전되어 있지 않다면 절차적 설계이다.
- 추상화와 구체적 사항이 서로 분리되어 있기 때문에, 이 코드는 유지보수하기가 훨씬 쉽다.
인터페이스 분리 원칙(ISP)
- ‘비대한’ 인터페이스의 단점을 해결
- 응집력이 약해짐
- 결국은 클라이언를 위해서 분해되어야 한다
인터페이스 오염
- 일부 클라이언트가 사용하지도 않는 인터페이스를 구현해야함
- 일부 구상체가 불필요한 인터페이스의 행위를 구현해야함
- 불필요한 복잡성 과 불필요한 중복성
클라이언트 분리는 인터페이스 분리를 의미한다
- 클라이언트가 자신이 사용하는 인터페이스에 영향을 끼치기 때문이다.
클라이언트가 인터페이스에 미치는 반대 작용
- 클라이언트의 요구사항 변경으로 인해 인터페이스가 변경되는 경우가 자주 생긴다.
- 이 상황에서 해당 인터페이스가 비대해서 여러 구상체를 지니고 있으면 그로 인한 영향 범위가 넓다.
- 그로 인해서 비용과 부작용의 위험성이 급격하게 증가한다.
인터페이스 분리 원칙(ISP)
클라이언트가 자신이 사용하지 않는 메소드에 의존하도록 강제되어서는 안 된다.
어떤 클라이언트가 자신은 사용하지 않지만 다른 클라이언트가 사용하는 메소드를 포함하는 클래스에 의존할 때, 그 클라이언트는 다른 클라이언트가 그 클래스에 가하는 변경에 영향을 받게 된다. 우리는 가능하다면 이런 결합을 막고 싶다. 따라서 인터페이스를 분리하기를 원한다.
다중 상속을 통한 분리
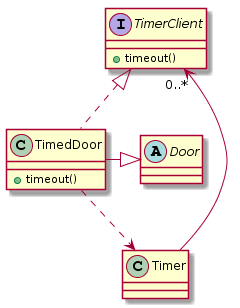
일반적으로 많이 쓰이는 기법이다.
복합체와 단일체
만약 인터페이스 복수 개(복합체)와 클래스 1개(단일체) 중 선택해야할 경우에는 인터페이스 복수 개(복합체)인 방식으로 구현하라.
당연하게 생각한다. 하지만 다들 지키지는 않는 것 같다. 만약 정 안되면 두 인터페이스를 통합한 인터페이스를 사용할 수도 있으나 권장하지 않는다.
결론
- 비대한 클래스는 클라이언트간 높은 결합도를 유발한다.
- 클라이언트 고유의(client-specific) 인터페이스 여러 개로 분해해야 한다.