알고리즘, 암호화키 만 보내는 경우가 일반적이며, 인코딩을 보내지 않는 경우도 심심찮게 확인할 수 있습니다.
그리고 샘플코드 라도 첨부파일로 보내주면 다행인데, 그렇지 않은 경우도 허다합니다.
일부 경우에는 검증되지 않은 블로그 포스트나 링크를 보내주고 그대로 해달라고 하기도 합니다.
참으로 답답한 현실이 아닐수가 없습니다. 저도 과거 주니어 시절에는 잘 모르고 위 처럼 의사소통을 하기도 하였는데,
지금 생각하면 얼굴이 붉어지는 일입니다 ㅠ
많은 개발자 들이 암호화에 대한 정확한 이해가 없이 의사소통을 하고 이런 방식이 어느 순간부터 대중화(?) 된 것 같습니다.
여기에 관련해서 해당 부분에 대한 간략한 이론적인 내용을 알아보고, 이제부터는 어떻게 암호화 스팩을 상호 간 공유해야 하는지 알아보겠습니다.
짚고 넘어가야할 부분은 여기서는 대중적으로 상호 간 통신 시 가장 많이 쓰이는 대칭키 암호화 방식으로 이야기 하겠습니다.
코드는 Java 기준으로 설명하겠습니다.
publicclassAES256CryptoimplementsCrypto{// 알고리즘/모드/패딩privatestaticfinalStringalgorithm="AES/CBC/PKCS5Padding";// 암호화 키privatefinalStringsecretKey;publicAESCrypto(StringsecretKey){if(secretKey.length!=256/8){thrownewIllegalArgumentException("'secretKey' must be 256 bit");}this.secretKey=secretKey;}// 암호화publicStringencrypt(Stringplain){Cipherc=Cipher.getInstance(algorithm);// TODOreturnnull;}...}
256 bit 암호화 방식이기 때문에 키 입력에 대한 유효성을 추가하였습니다. - 아직은 논란이 있는 코드입니다.
key size가 암호화 알고리즘의 bit 수를 가르키는 것과 동일하게 됩니다.
즉 AES256 이라는 것은 암호화 키 사이즈가 256 bit 라는 말과 동일합니다.
초기화 벡터, block size
publicclassAES256CryptoimplementsCrypto{// 알고리즘/모드/패딩privatestaticfinalStringalgorithm="AES/CBC/PKCS5Padding";// 암호화 키privatefinalStringsecretKey;// 초기화 벡터privatefinalStringiv;publicAESCrypto(StringsecretKey,Stringiv){if(secretKey.length!=256/8){thrownewIllegalArgumentException("'secretKey' must be 256 bit");}if(iv.length!=128/8){thrownewIllegalArgumentException("'iv' must be 128 bit");}this.secretKey=secretKey;this.iv=iv;}// 암호화publicStringencrypt(Stringplain){Cipherc=Cipher.getInstance(algorithm);// TODOreturnnull;}...}
AES의 block size는 128 bit 고정이기 때문에 별 다른 변화가 없습니다.
AES의 모태가 되는 Rijendael알고리즘 경우에는 128 192 256 bit이기 때문에 달라질 수 있습니다.
단, 초기화벡터(iv)의 경우 block size와 같아야 하기 때문에 128 bit 여야합니다.
iv의 경우 더 강력한 암호화를 위해서는 암호화 요청 시 마다 달라지는 것이 보안에 더 좋으나,
예제이므로 우선은 초기 세팅으로 표현하겠습니다.
갑자기 새로운 인터페이스가 추가되었습니다.
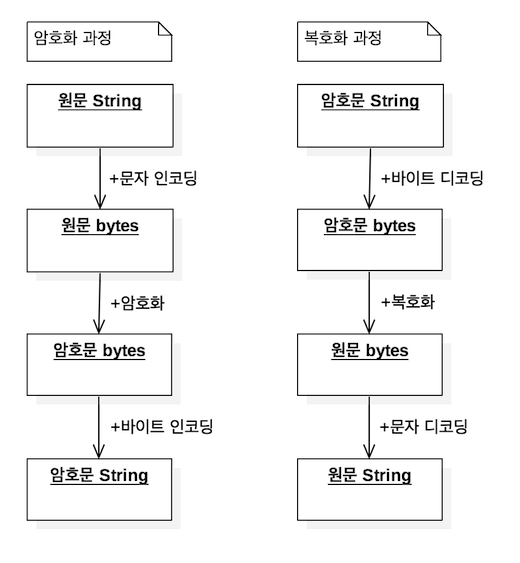
암호문을 인코딩 하기 위해서는 위와 같은 인터페이스가 필요하기 때문입니다.
간단하게 설명하면 string -> bytes 가 encode이며, bytes -> string 는 decode입니다.
기본적으로 인코딩은 charset와 연관관계가 깊은 문자인코딩으로 생각하기 쉬운데, 암호화의 경우에는 암호화로 인해
문자인코딩과는 별개의 규칙이 없는 bytes가 반환되므로 문자로 표현할 수 없게 됩니다.
고로 암호문을 위한 인코딩 은 1차적으로 문자(charset)와 연관없는 인코딩이 가능해야합니다.
즉 문자열을 기준으로 해서 byte화 시키는 문자인코딩과는 다르게 bytes를 기준으로 문자열화 시키는
인코딩 방식이 필요 하게 됩니다.
가장 간단하게는 bytes를 16진수 기반으로 표현하는 Hex 방식이나 Base64 방식을 사용하는 것이 좋습니다.
위 구현체를 바탕으로 AES256Crypto 를 계속 구현해 보겠습니다.
아까 예시에서 정의한 “암호문 인코딩 방식 : Base64 + UTF-8” 에서 UTF-8 은 이후에 나옵니다.
Base64Encoder에 정의된 것과 혼동하면 안됩니다. : base64 스팩 자체가 ASCII에 의존하는 방식입니다.
publicclassAES256CryptoimplementsCrypto{// 알고리즘/모드/패딩privatestaticfinalStringalgorithm="AES/CBC/PKCS5Padding";// 암호화 키privatefinalStringsecretKey;// 초기화 벡터privatefinalStringiv;// 문자인코딩 방식privatefinalStringcharset="UTF-8";// 암호문 바이트 인코더privateEncoderencoder=newBase64Encoder();...// 암호화publicStringencrypt(Stringplain){// 암호화 키 생성byte[]keyData=secretKey.getBytes("US-ASCII");SecretKeysecureKey=newSecretKeySpec(keyData,"AES");Cipherc=Cipher.getInstance(algorithm);// 암호화 키 주입, iv 생성 주입, 초기화 - 이상하지만 우선 무시c.init(Cipher.ENCRYPT_MODE,secureKey,newIvParameterSpec(iv.getBytes("US-ASCII")));// 문자인코딩 방식을 통한 string -> byte 변환 후 암호화byte[]encrypted=c.doFinal(plain.getBytes(charset));// encoder#encode를 통한 byte -> string 변환returnencoder.encode(encrypted);}...}
객체 변수로 charset 항목이 UTF-8로 추가되었습니다.
그리고 encoder 객체도 default로 생성된 상태입니다.
입력받은 plain은 문자열 이기 때문에 문자인코딩 방식을 통해서 byte로 변환하겠습니다.
// 문자인코딩 방식을 통한 string -> byte 변환plain.getBytes(charset)
Java에서는 기본적으로 String#getBytes(String charset) 메소드가 있기 때문에 이것을 이용해서 bytes로 변환하였습니다.
암호화 한 후 bytes 로 반환된 값을 문자열로 출력해야하는데 이럴 경우에는 바이트 인코딩 방식이 필요합니다.
위에서 미리 선언해 둔 Encoder인터페이스를 통해서 변환하겠습니다.
// encoder.encode를 통한 byte -> string 변환encoder.encode(encrypted);
갑자기 매우 단순한 키 인코더 구현체가 나와서 당황스러울 듯 합니다.
하지만 키 인코딩의 경우 문자인코딩, 바이트인코딩 방식 둘 다 가능하기 때문에 위와 같이
Encoder 인터페이스를 통한 구현체를 제공하는 것이 다형성이 도움이 되기 때문에 이렇게 구성해보았습니다.
지금의 예제는 ASCII 방식으로 암호화 키와 초기화 벡터를 제공하지만 이런 경우에는 키 bytes 구성이 아스키 기반으로 인해서 단순해 집니다.
고로 가능하면 다양한 바이트 구성이 가능한 base64나 hex를 이용해서 키 bytes를 제공할 수 있게 하는 것이 보안에 유리합니다.
우선 예제를 위해서 위 StringEncoder를 사용하는 것으로 진행하겠습니다.
*중요한 점은 위 인코더는 문자인코딩 방식이기 때문에 암호문 인코더로 사용하면 정상적인 암/복호화가 불가능 하게 됩니다.**
암호문 구현체에 키 인코더 주입 후 변경
publicclassAES256CryptoimplementsCrypto{// 알고리즘/모드/패딩privatestaticfinalStringalgorithm="AES/CBC/PKCS5Padding";// 암호화 키privatefinalStringsecretKey;// 초기화 벡터privatefinalStringiv;// 문자인코딩 방식privatefinalStringcharset="UTF-8";// 암호문 바이트 인코더privateEncoderencoder=newBase64Encoder();// 키 인코더privateEncoderkeyEncoder=newStringEncoder("US-ASCII");...// 암호화publicStringencrypt(Stringplain){// 암호화 키 생성 - keyEncoder를 이용byte[]keyData=keyEncoer.encode(secretKey);SecretKeysecureKey=newSecretKeySpec(keyData,"AES");Cipherc=Cipher.getInstance(algorithm);// 암호화 키 주입, iv 생성 주입, 초기화 - iv의 경우 keyEncodr를 이용c.init(Cipher.ENCRYPT_MODE,secureKey,newIvParameterSpec(keyEncoer(iv));byte[]encrypted=c.doFinal(plain.getBytes(charset));returnencoder.encode(encrypted);}...}
keyEncoder를 이용해서 암호화 키와 초기화 벡터를 bytes로 성공적으로 변환하였습니다.
여기에서 keyEncoder의 경우 ASCII charset을 기반으로 생성하였는데, 대부분의 경우 암호화 키를
예제(12345678901234567890123456789012)와 같이 영어와 숫자 또는 특수문자 기반으로 문자열을 제공하기 때문에 ASCII 만으로도 충분합니다.
만약 한국어 등을 이용한다면 해당 문자를 표현할 수 있는 charset(ex:UTF-8, EUC-KR)로 변환해야 합니다만 그런 케이스는 거의 없을 것입니다.
위에도 설명했지만 가능하면 문자열 키도 base64 과 같은 바이트 인코딩 방식으로 제공하는 것이 보안에 좋습니다.
복호화 메소드 구현
publicclassAES256CryptoimplementsCrypto{// 알고리즘/모드/패딩privatestaticfinalStringalgorithm="AES/CBC/PKCS5Padding";// 암호화 키privatefinalStringsecretKey;// 초기화 벡터privatefinalStringiv;// 문자인코딩 방식privatefinalStringcharset="UTF-8";// 암호문 인코더privateEncoderencoder=newBase64Encoder();// 키 인코더privateEncoderkeyEncoder=newStringEncoder("US-ASCII");...// 복호화publicStringdecrypt(Stringcipher){// 암호화 키 생성 - keyEncoder를 이용byte[]keyData=keyEncoer(secretKey);SecretKeysecureKey=newSecretKeySpec(keyData,"AES");Cipherc=Cipher.getInstance(algorithm);c.init(Cipher.DECRYPT_MODE,secureKey,newIvParameterSpec(keyEncoer(iv));// encoder.decode 를 통해서 string -> bytes 변환byte[]encrypted=encoder.decode(cipher);// 복호화 후 문자인코딩 방식을 통한 byte -> string 변환 후 반환returnnewString(c.doFinal(encrypted),charset);}}
암호화와는 반대로 진행하는 것을 확인할 수 있습니다.
암호화
String#getBytes(String)(문자 인코딩)를 이용해서 bytes로 변환
암호화
encoder.encode(바이트 인코딩)를 이용해서 String으로 변환
복호화
encoder.decode(바이트 디코딩)를 통해서 bytes로 변환
복호화
new String(byte[], String)(문자 디코딩)을 이용해서 String으로 변환
구현체에 중복코드가 많아서 약간의 리펙토링을 진행하고 전체코드를 보겠습니다.
AES256Crypt 리펙토링
publicclassAES256CryptoimplementsCrypto{publicstaticfinalintKEY_SIZE=256;publicstaticfinalintBLOCK_SIZE=128;privatestaticfinalStringAES="AES";// 알고리즘/모드/패딩privatestaticfinalStringalgorithm=AES+"/CBC/PKCS5Padding";// 암호화 키privatefinalSecretKeysecretKey;// 초기화 벡터privatefinalIvParameterSpeciv;// 문자인코딩 방식privatefinalStringcharset="UTF-8";// 암호문 인코더privateEncoderencoder=newBase64Encoder();// 키 인코더privateEncoderkeyEncoder=newStringEncoder("US-ASCII");publicAESCrypto(StringsecretKey,Stringiv){this.setSecretKey(secretKey);this.setIv(iv);}privatevoidsetSecretKey(StringsecretKey){byte[]keyBytes=keyEncoder.encode(secretKey);if(keyBytes.length!=KEY_SIZE/8){thrownewIllegalArgumentException("'secretKey' must be "+KEY_SIZE+" bit");}this.secretKey=newSecretKeySpec(keyBytes,AES);}privatevoidsetIv(Stringiv){byte[]ivBytes=keyEncoder.encode(iv);if(ivBytes.length!=BLOCK_SIZE/8){thrownewIllegalArgumentException("'iv' must be "+BLOCK_SIZE+" bit");}this.iv=newIvParameterSpec(keyEncoer(iv)}// 암호화publicStringencrypt(Stringplain){Cipherc=Cipher.getInstance(algorithm);c.init(Cipher.ENCRYPT_MODE,this.secretKey,this.iv);byte[]encrypted=c.doFinal(plain.getBytes(charset));returnencoder.encode(encrypted);}// 복호화publicStringdecrypt(Stringcipher){Cipherc=Cipher.getInstance(algorithm);c.init(Cipher.DECRYPT_MODE,this.secureKey,this.iv);byte[]encrypted=encoder.decode(cipher);returnnewString(c.doFinal(encrypted),charset);}}
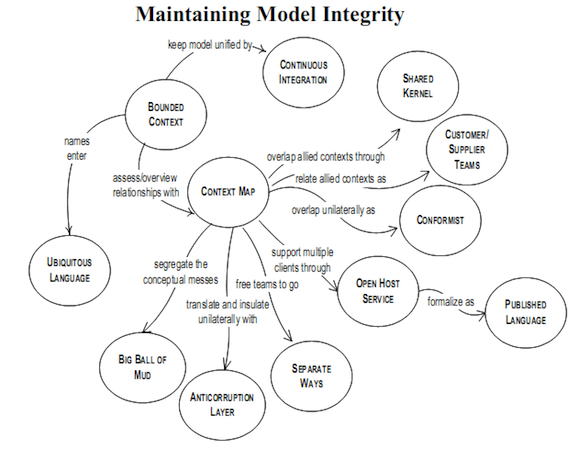
DDDQ(Domain Driven Design Quickly) - 도메인 주도 설계란 무엇인가? 라는 책의 간단 요약 정리
지속적인 리팩터링
설계와 구현사이 피드백을 통한 코드 고도화
코드 리펙터링
애플리케이션의 기능에 변화를 주지 않고 코드를 더 좋게 만들기 위해 재설계하는 절차
많은 방법론과 패턴이 존재한다.
DDD 리펙터링
프로젝트 진행 중에 도메인에 대한 새로운 통찰이 생기고 어떤 것들은 점점 명확해지며, 둘간의 관계가 발견되기도 한다.
이러한 것은 모두 리펙터링을 통해 설계에 반영되어야 한다.
위와 같은 깊은 통찰 을 위한 리펙터링은 패턴이 존재하지 않는다.
모델링 : 비즈니스 명세서를 읽고 명사와 동사를 찾는 것이다. 명사는 클래스로 동사는 메소드로 변환된다.
하지만 위와 같은 기본적인 모델링 은 아주 심한 단순화이며, 여기에서 점점 깊은 통찰을 가지도록 개선(refactor) 해야 한다.
유연한 설계가 바탕이 되어야한다. 유연하지 못하면 개선 에 따른 비용이 커진다
가능한 작은 단위로 나누어서 진행해야 한다.
정교한 도메인 모델은 도메인 전문가와 개발자들이 밀접하게 엮인 조직이 반복적으로 리팩터링을 수행하지 않는다면 만들어질 수 없다.
핵심 개념 드러내기
리펙터링은 작은 단계로 나누어 진행되며, 그 결과 작은 개선의 연속으로 나타난다. 그런데 소규모의 변경이 큰 차이를 초래하는 경우가 있다.
바로 이것이 도약(Breakthrough) 이다.
어떤 암시적 개념이 핵심개념이며, 이것을 명시적 개념으로 모델링하게되면 도약의 기회가 생긴다.
암시적개념 : 도메인 전문가와 이야기할 때 외부로 노출되지 않은 것
암시적 개념을 발견하는 방법
언어를 주의 깊게 듣기
설계 영역에서 분명하지 않는 부분을 주의 깊게 들여다 보기
지식체계(모델링 관계 설정 등)를 만들 때 모순에 부딪칠 경우
해당 도메인의 문헌을 활용 - 기존예시
(암시적인 것을) 명시적인 개념으로 만들어 낼 때 유용한 추가개념
제약조건(constraint)
불변식(invariant)?를 표현하는 간단한 방법
예제
as-is
publicclassBookshelf{privateintcapacity=20;privateCollectioncontent;publicvoidadd(Bookbook){if(content.size()+1<=capacity){content.add(book);}else{thrownewIllegalOperationException("The bookshelf has reached its limit.");)}}}
제약사항 메소드 분리를 통한 리팩토링 후
publicclassBookshelf{privateintcapacity=20;privateCollectioncontent;publicvoidadd(Bookbook){if(isSpaceAvailable()){content.add(book);}else{thrownewIllegalOperationException("The bookshelf has reached its limit.");)}}// 제약사항 메소드 분리privatebooleanisSpaceAvailable(){returncontent.size()<capacity;}}